
 Please refer to the word numbers problem on this page. Before I even explain how I tried to solve this problem, you can download and install the code from my bitbucket word-nums repository. After you have tried finding numbers and are convinced that this application does solve the problem, if you are interested in understanding the details of the solution, you may continue reading. AnalysisThe characteristics of the problem are:
Finally, we first need to convert a given number into its word equivalent. The algorithm to do the conversion is described next.  Some analysis 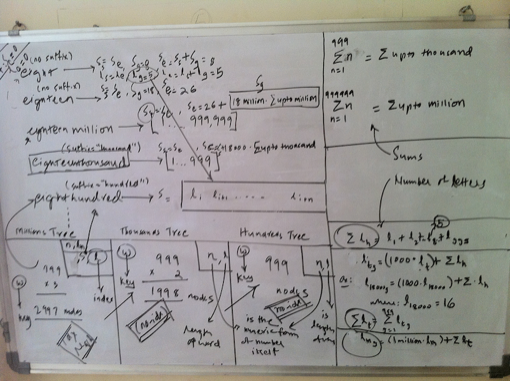 Some more analysis Converting a number into it's word equivalentIt can be observed that any number is a repetitive pattern of 1 to 999, scaled by thousand for the next pattern and by million for the next and so on. In our case, we scale only upto millions. Thus it would suffice to generate a word equivalent of a 3 digit number between 1 and 999 and use the scaling factor of thousand and million based upon the number of times the pattern is repeated. Further for a 3 digit number, any digit that occurs in unit’s or hundred’s place is a simple look up from the numeric form of the digit to its word form. However the translations for the digit in ten’s place are best described as quirky as 1 in ten’s place means ten if followed by 0 in units place, 11 if followed by 1 and so on. The digits 2 to 9 in ten’s place are less quirkier as the conversion depends only on the digit and not by the digit in unit’s place as is the case for 1 in ten’s place. Thus,it is now possible to generate word equivalent for any number by splitting it into patterns matching a 3 digit number and using the appropriate scale such as thousand and million. The code that generates a word equivalent is shown here. (defun join-words (words) How about brute force?Having identified that an index b-tree is a suitable data structure for our needs, and we have already figured out the generation of a word equivalent, it would be straightforward to generate an indexed b-tree of billion numbers. We can then traverse the tree in sorted order to update the index which is the number of letters covered. Then a simple lookup using the index should suffice. However this approach will suffer from the problem of time to build an index, sorted b-tree as we have a billion numbers. The time is dependent upon the processing power and memory availabe on the machine that builds the data structure. Of course, we could use a large number of machines (or multiple cores) so that we can build the data structure faster. Even in that case, we still have to ensure that we distribute the numbers evenly between the machines so that all parallel computations complete around the same time! But would there not be an elegant way out? It turns out, there is! Elegant way outWe have already identified that there is a repititive pattern of digits. We used this property to generate a word equivalent. Then the same property should be helpful in lexicographical ordering of the words. Is this true? Let us find out. If we sort just the first 999 numbers, the sorted list (A) looks something as shown below: 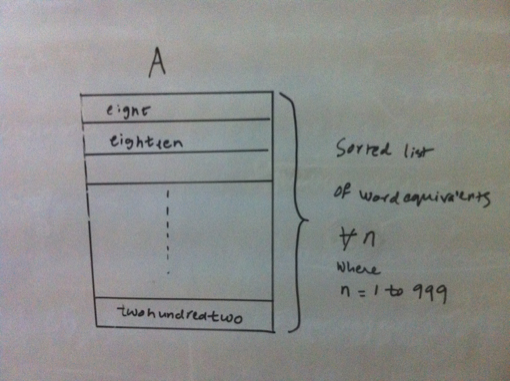 First 999 numbers in lexical order Now consider the numbers upto 999,999. These are actually a group of 999 numbers where each group starts with [1000;2000;3000;999,000]. Their word equivalents are [onethousand,twothousand,threethousand,..,ninehundredninetyninethousand]. These word equivalents can be generated by adding the suffix ’thousand’ to the word equivalents of numbers from 1 to 999, which is our pattern (building block). So the sort order for the numbers upto 999,999 remains the same when expressed as a group of numbers as described above. Further each such group contains an additonal 999 numbers, which happen to be 1 to 999. The same argument holds true for numbers upto 1 billion. Just that a group in this case will contain 1 million numbers. Overall the three sorted lists A, B, C respectively of multiples of one, thousand and million are shown below. 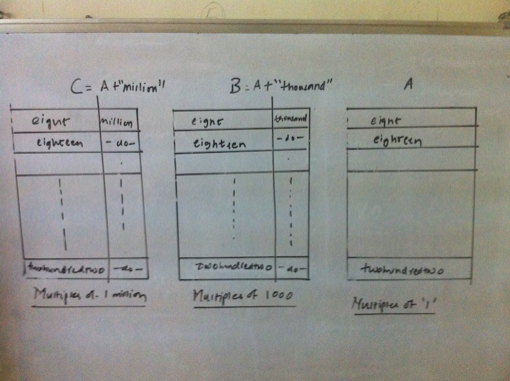 Multiples of 1, 1000 and 1,000,000 in lexical order Since any number is either a million or thousand or hundred, we just need to know the lexicographical position of the successive scales starting from the highest scale. Thus for a number that is multiple of million, I need to find out the sorted order position of the millionth part of the number, followed by that for the thousandth part and then for the hundredth part. As we have a billion numbers to look at, we need to maintain the following 3 databases:
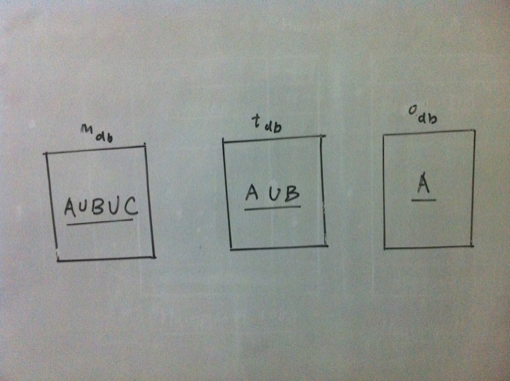 Databases containing multiples of (1 1000 and 1000000), (1 and 1000) and 1 in lexical order Now if we can precompute the number of letters counted and the sum, we can have an elegant solution to our problem. Precomputing the sum and number of lettersSince we know the word equivalent of a number, we also know its length. For a number that represents a multiple of one, its length can be denoted as: \(l_i\). A number that is multiple of 1 is the smallest scale and we need to look no further. So the overall sum of all letters in word equivalents of numbers that are multiple of 1 can be represented as: $$l_{ones} = \sum_{i=1}^{999} l_i$$ Now lets consider a number that represents a multiple of thousand. Let the length of its word equivalent be denoted by \(l_t\). Since such a group contains further 1000 numbers, the length for the group can be described as $$l_{tg} = l_t + l_{ones}$$ So the total number of letters covered upto 1 million can be denoted as $$l_{thousands} = \sum_{g=1000}^{999000} l_{tg}$$ Similary for a multiple of millions, the formula is $$l_{mg} = l_m + l_{thousands}$$ So the total number of letters covered upto 1 million can be denoted as $$l_{thousands} = \sum_{g=1000}^{999000} l_{tg}$$ Similary for a multiple of millions, the formula is $$l_{mg} = l_m + l_{thousands}$$ Here we do not need to compute the overall summation as we are scaling only upto a billion. On the same lines, the sum of numbers covered can also be computed. $$s_{thousand} = \sum_{i=1}^{999} i$$ $$s_{million} = \sum_{i=1}^{999999} i$$ $$s_{tg} = t + s_{thousand}$$ where t = (1000 or 2000 or ... 999000) $$s_{mg} = m + s_{million}$$ where m = (1000,000 or 200,000 or 999,000) AlgorithmNow we can describe the entire algorithm. As a first step, we build the 3 databases which contains the multiples of one, thousand and million. Each database is an indexed btree. Next we update the btree which contains the multiples upto million with the sum and letters covered using the formuale described in the previous section. Now given the number of letters covered, which is actually an index into our database, we look up the number starting with the millions database using this index. We find the first node n in the btree such that for this node n, if index is \(k_found\), $$k_{found} >= index$$ If \(k_{found}\) is index, we have found our number. Else, we navigate to the previous node in the tree and check if that is the node we are looking for by computing the number of letters covered. Otherwise, this node forms a part of number and serves as a key into the next database, which is thousands database if it is multiple of thousand or one’s database. Before searching in the next database, we update that database with the letters and sums on each node, as the key is a prefix to each number in the next database., Every node of the binary tree contains the following data:
(defun find-integer (idx db &optional (n 0) (sum 0) (vals (list 0 0))) A visual depiction of the algorithm is shown below. 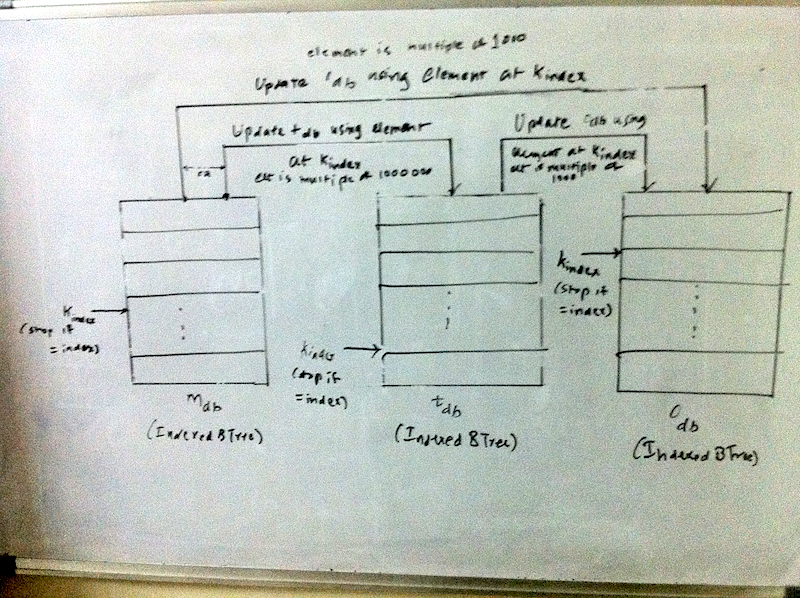 Word numbers algorithm Since we use an indexed B-Tree, the efficiency of the algorithm while creating and updating a btree is $$O(n (log n))$$ while looking up the number is $$\approx O(log n)$$. Hence the overall efficency is: $$O(n (log n))$$ DisclaimersThe solution is tested on SBCL 1.0.39 on Mac OS X 10.6 using cl-elephant as the btree implementation. I would like to emphasize that the solution was not generated in the sequence described above. I did some detailed whiteboarding and tried out code snippets and finally figured out the solution. Further, the solution uses only \(999 * (3 + 2 + 1) = 5994\) nodes. So an in-memory version of a binary search tree should as well suffice. Since I had a ready to use disk based indexed B-Tree implementation, I chose to use that. What is the number at 51th billion letter?As per my solution, there is no number that ends at 51 billion. In fact, there is a number that ends at 51 billion and one. And that number is 676465328. The sum of numbers upto that point is 206392395198132239862723. From the code run at REPL * (word-nums:find-at 51000000001)
0 Comments
 Please refer to the sling blade problem on this page. Before I even explain how I tried to solve this problem, you can download and install the code from my bitbucket ol-titles repository. After you have tried finding overlapping titles and are convinced that this application does solve the problem, if you are interested in understanding the details of the solution, you may continue reading. AnalysisThe problem requires us to find the longest chain of overlapping titles. The following can be identified from the problem details:
Thus we have a directed graph to reprsent the titles. Now the problem of finding the longest chain gets transformed into the problem of finding a path within this graph which covers as many vertexes as possible. At least theoretically, then the longest chain will be the path that covers each vertex and that too exactly once, since we are not supposed to repeat titles. 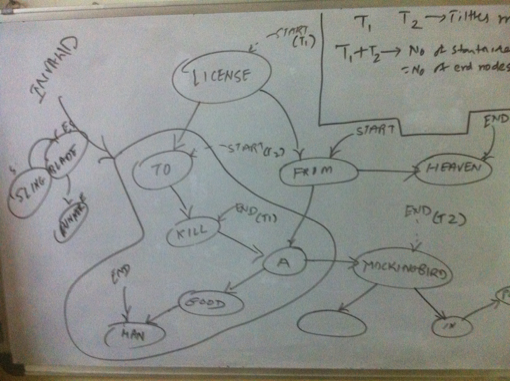 Analysis While prototyping all the different ideas and approaches in code, I used the cl-graph library by Gary King. So wherever you read something as ’I tried’ it implies as in ’tried in code’. I have not shown all the code but only the one that I chose as a solution. Traveling Salesman ProblemThe problem of finding the path in a graph which covers each vertex exactly once is the traveling salesman problem and we know it is an NP Complete Problem. In our case, since we have directed edges, where weight of each edge is 1, it becomes the Hamiltonian cylce problem. But we have a directed graph at hand. A heuristic to find the Hamltionian path is to find minimum spanning tree of a graph and finding the shortest paths between the vertexes of the tree ordered by depth first traversal. However this works only for undirected graphs. Anyways, how do you find tree of a directed graph? However this analysis clearly shows that we cannot have a chain that covers all titles unless its an undirected graph. Attempt 1: Assuming an undirected graphGoing by the previous argument, I tried with an undirected graph and produced an ordering of the vertexes in depth first traversal of the minimum spanning tree. Now while finding the paths between these vertexes, I actually look at the directed version of the graph. The problem with this approach is that you find a long chain only if you reach a vertex that is a leaf late enough in the cycle. This is evident from the visual below. Hence this transformation is not suitable for our problem. 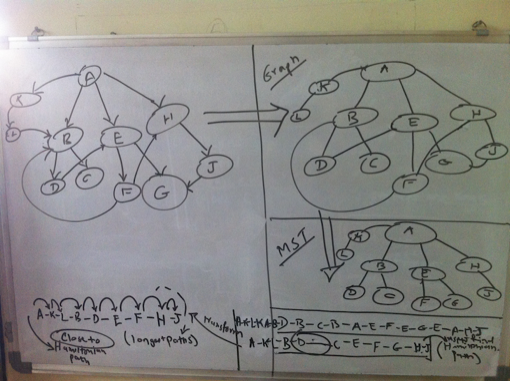 Attempting with a MST of undirected graph Again we could actually find the optimum branchings (minimum spanning tree) of a directed graph, but still the vertexes obtained from the branching could suffer from the same problem. So I dropped this idea. Attempt 2: Topological SortAs a first step, I removed all the edges from the edge that would result in creation of cycles. Now I have a directed acyclic graph and you can do a topological sort. I then tried to find the path between two vertexes at the opposing ends of the sorted list of vertexes as shown in visual below. Again this usually produced a chain of around 20 titles. Again here ideally we must try to find the path between the pairs of vertexes which are ordered by their position in the topological sort. Still attempting to find the path by successively moving deeper into the sorted list at both the ends gave me a fair enough idea to follow this path or not. Not happy with the results, I abandoned this idea as well. 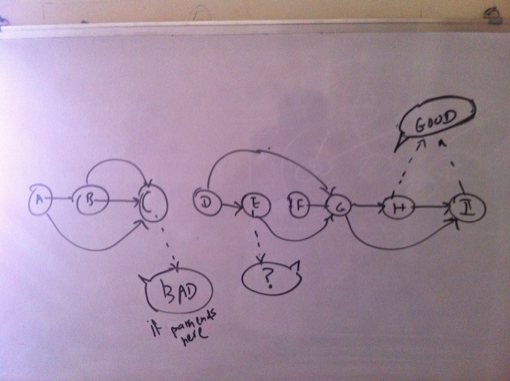 Attempting with a topological soft of directed acyclic graph Attempt 3: Cyclic ApproachFinally this is what I came up with. I first found out if they directed graph is connected. It was disonnected. So I found the largest connected component. I chose this component to find the longest path. Next I figured if it was cyclic or not. It was. So I found all the vertexes which belong to a cycle. Next was to find a path for each cyclic vertex such that the path contains only cyclic vertexes. The largest such cyclic path would be my answer to the longest chain. This is the property that I applied here usefully. In order to prove a vertex is cyclic, we can determine a path where the vertex in question is the start as well as the end node. However the coroallary of this is that every vertex on the the cyclic path is cyclic itself. As such we can find a path of overlapping titles where each vertex on the path is cyclic, because for a given cyclic vertex, one of its neighbors has to be cyclic! Implementing this, I was able to find out a chain of 230 titles. Thus by using the heuristic of finding longest cyclic path so that it contains only cyclic vertexes, I was able to find a heuristic solution to the longest chain. We can also claim that the longest chain which is a cyclic chain cannot be more than the total number of cyclic vertexes. 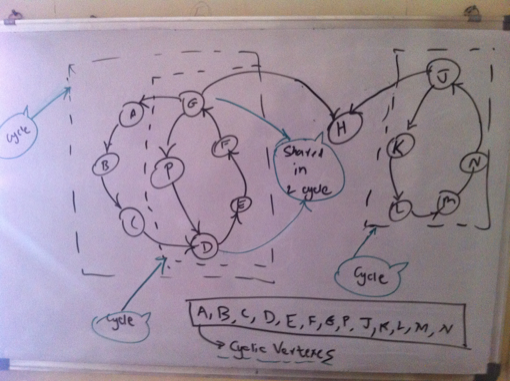 Finding out the largest cyclic path containing only cyclic vertexes AlgorithmThe algorithm can thus be described as: Build a directed graph of the titles where each directed edge (u, v) represents an edge from title ’u’ to overlapping title ’v’. Then find all the cyclic vertexes of the largest connected component of the directed graph. Find the cyclic path for each cyclic vertex such that the path contains only cyclic vertexs. The longest such path is the longest chain of overlapping titles, given the heuristics.
Since the main task is to find out the cyclic vertexes (using depth first search), let us assume we have a graph G=(V, E) which represents the largest connected component. Since we find out if each vertex V is cyclic, the efficiency turns out to be: \( O(V . (|V| + |E|)) \approx O({|V|}^{2}) \) When we find the cyclic path, we do not do a depth first search and only look up in the list of cyclic vertexes for the next valid vertex for the given vertex  Any programmer who is learning Lisp and sticks with it, eventually comes face to face with Macros. While trying to come to terms with the concept of macros and its usage, he often comes across a statement which can be stated as ”Once you really understand macros, you will understand why lisp needs parentheses.” Though the statement is correct, you may not find a direct or simple explanation of its meaning. I attempt to do that here. Defining a new control flow operatorLet us assume you have a requirement to process only non prime numbers, given a list of numbers. Also assume, you have a function available that tells you given a number, if it is prime or not. Intutively, this is what you want to express ”Unless it is a prime number, do the processing” given the fact that we have a predicate to check primes. However what you see is that C does not have unless control flow operator. So you write: if(!prime(...)) { However, this is what you would have preferred and in fact you would read the above code as below: unless(prime(...)) { You think ”It would have been great, if the language simply allowed me to add the operator”. You might also naively think that this must not be so hard. If I can write and abstract my own computations as functions, why cannot I introduce my own operators, specific to my problem? The answer (if you may hazard a guess), is that it is not so simple to provide the feature to add new constructs. We have to dig deeper to find out the answer. What happens to the code?Let us now navigate into the compiler world. Sticking to the compiler basics, let us try to find out what shape your code transforms into when the C compiler handles the if construct. As you may know, the compiler front end builds a parse tree. So your source code is transformed into a tree as shown below. (I have shown the tree for the if operator). 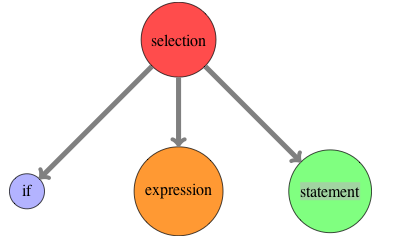 Parse tree for if operator Now let us try to employ our imagination. If we assume that there was an ’unless’ operator like if, what would the abstract syntax tree look like. It is shown below: 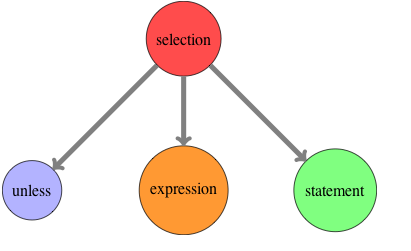 Parse tree for unless operator Thus we have found a potential solution to allowing a language to introduce a new operator. Whenever C compiler encounters an unless keyword, it has to generate the syntax tree something similar to figure . For that we have to look into the process it employs for the existing ’if’ operator. The reason why C compiler can transform ’if’ is that it ’knows’ the syntax of ’if’ beforehand. It is embedded inside the compiler. So in order for the C compiler to understand new ’unless’ like constructs, we have to define a mechanism to specify the syntax of your new operators. And therein lies the crux. How can the compiler understand new syntax?What then could be the simplest way to help the compiler understand new syntax? It would be by having a consistent, uniform syntax. Is the syntax of C consistent, uniform? No. Is the syntax of Lisp consistent, uniform? Yes. In fact, uniform syntax is equivalent to no syntax. Now you get why parentheses are required. They lend very well to the requirement of uninform syntax.[1] Hence I conclude that macros are not impossible but very hard in other languages because:
Recommended Reading   [1] This is also related to the concept of internal and external domain specific languages. Any which ways, external domain specific languages are nothing but bloated tools on top of languages which got the design of syntax wrong in the context of allowing new operators or a probelm / domain specific language to be defined (which is nothing but a set of related operators to solve the problem at hand).
[2] This does not imply that simply a uniform syntax allows a compiler to handle new syntax with ease. There is some more important stuff in addition to uniform syntax, but I understand that it is a key requirement. |

MeI am a 3D graphics software engineer. 
Archives
December 2011
Categories
All

me @ delicious
|
 RSS Feed
RSS Feed
