
|
Please refer to the mystery M function problem on this page. Analysis(defun m (i j k) Let us look at the exit conditions for this recursive function ’m’. One of the exit conditions is when k equals zero. Now look at the recursive call. The recursive call fetches a value of k by replacing it with a call to ’m’ while decrementing k. As such k will reach 0, when it will return 1. So it can be seen that the terminating condition of k equals zero returns 1 which is used as a value for k itself. EvaluationThe evaluation will never terminate!
0 Comments
 Please refer to the landmarks web app problem on this page. AnalysisThe key part to solve here is to pick the nearby landmarks. As such we need to define what nearby means. Since each landmark’s latitutde and longitude are defined, we can define for a given landmark lm, whose latitude and longitude are \(lm_{lat}\)and \(lm_{long}\) respectively; a nearby landmark nlm with latitude and longitude \(nlm_{lat}\) and \(nlm_{long}\) such that: The nearest \(nlm_{lat} < lm_{lat}\)OR The nearest \(nlm_{lat} > lm_{lat}\) OR The nearest \(nlm_{long} < lm_{long}\) OR The nearest \(nlm_{long} > lm_{long}\) In other words, the nearest landmark in any direction to the given landmark assuming the given landmark as a center. If we can now think of a landmkark as a vertex on a graph, then the neighboring vertexes of a given landmark will be those landmarks that satisfy the above definition. AlgorithmBuild a B-Tree where key is latitude and another where key is longitude. Now do a inorder traversal of this BTree while adding a landmark as a key to a hash table and its nearest landmarkes as values. Then given a landmark, we just look up in the hash table to find the nearest landmarks. ImplementationIn order to make the web application responsive, it would be nice to load the page with a javscript hashtable of landmarks and its nearby landmarks.
 Please refer to the decrypting the two time pad problem on this page. AnalysisThe following are the problem characteristics. It is an instance of:
Algorithm
ImplementationI have not implemented this algorithm. But the analysis and the requirements of the problem do indicate that an approximate solution is requi Ared and the quality of it will hence depend upon (drawn from the algorithm) the chosen reference text. As such we may have to try out the implementation with mulitple chosen texts. References Please refer to the ascii a-maze problem on this page. AnalysisA maze is a grid of n * m cells. Given a maze, we can detect from a given cell k, which cell you can move to next. This is a defintion of a directed graph. Thus we can model a maze as a directed graph where each cell of the maze is a vertex and its neighbors are the cells you can navigate to from the given cell. Now the start and end cells are defined as the bottom left and top right cells. Counting the lowest row as 1st row and left most column as 1st column while assuming m rows and n rows in the maze, the start cell is (1,1) while the end cell is (m, n). The problem then becomes of finding the shortest path between the start and end cells. AlgorithmThis is the Breadth-First-Search algorithm to find shortest path between two vertexes.
The important piece here will be to transform the ascii maze into the graph and ignoring the cyclic vertexes while finding the shortest path. 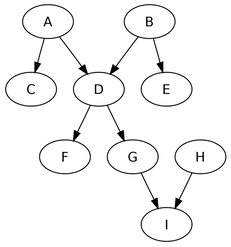 Please refer to the add-a-gram problem on this page. AnalysisGiven a 3 letter word, let us assume, we can find out the 4 letter words that are its add-a-grams. We can then expand this to a n letter word pointing to its (n + 1)th add-a-gram. We can obviously model this as a directed graph where each word points to its add-a-grams. Further since there is no possibility of an add-a-gram pointing to its possible source, this will be an acylic graph. Thus we have a directed acyclic graph representing the add-a-grams. AlgorithmThe problem then is of finding the ’longest path’ in the directed acyclic graph. In our case each edge will have a weight of 1.
First we build a hash table where key is the length of the word and values are the words of those length. Then we build the directed acylic graph such that each vertex is the word ’w’ and its neighbors are its add-a-grams obtained by searching through the hash table those words which are 1 more character in length than the given word ’w’. |

MeI am a 3D graphics software engineer. 
Archives
December 2011
Categories
All

me @ delicious
|
 RSS Feed
RSS Feed
