
 Please refer to the Tour the T problem on this page. AnalysisThis is an instance of the Traveling Salesman Problem. We can model the entire subway as a weighted graph G=(V,E) where V is a station and E is an edge that connects two stations and w is the weight of the edge that represents the travel time between the two stations. Algorithm
 Please refer to the strawberry fields problem on this page AnalysisThink of each strawberry as a point on an XY plane. Then we can find out the concave hull which is the smallest polygon that contains all the ponits or strawberries. 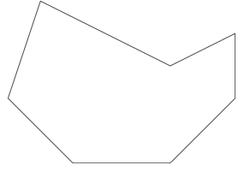 Assume for some given strawberry field, the concave hull is something like this 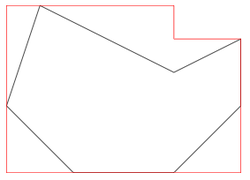 Now walk through the vertices of the concave hull in succsession. For each pair of successive vertexes, find the point of intersection that is outside the concave hull. This will now result in an updated polygon as shown. 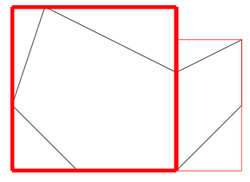 Finally pick the largest edge and from the two edges, one of which succeeds the largest edge and the other which precedes it, pick the larger one. Form a rectangle between the largest edge and the selected succeessive or preceding edge. This is depicted here. 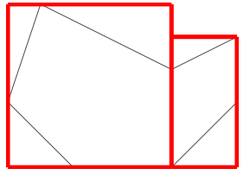 Now choose all points of the concave polygon that lie outside the rectangle that we just derived. Add to this set of points, a point that would have been derived as a result of deriving the rectangle. Repeat the process of forming the rectangle till all points of concave polygon are covered. For the sample, the final result is shown. AlgorithmThe steps of the algorithm are enumerated below.
 Please refer to the setless set problem on this page.
It can be easily deduced that the collection of 81 cards, contiains 27 SETs where each set contains the same cards. Now in order to find the number of ways in which we can collect 20 cars such that it contains no set, we can use the following formula: $$ N_{20\,cards\,without\,set} = N_{all\,possible\,collections\,of\,20\,cards} - N_{collection\,of\,20\,cards\,with\,atleast\,1\,set}$$ Find out set with different cards Now if \(n_{same}\) is the number of sets with same cards, we already know that $$n_{same} = 27$$ If we want to form a set that contains different cards, we can first pick an equal set and then pick a card from that set. Repeating this thrice will give us a set that contains different cards. Thus total number of sets with different cards \(n_{different}\) can be defined as $$n_{different} = (27 * 3) * (26 * 3) * (25 * 3) $$ Thus total number of possible sets \(n_{sets}\) can be defined as: $$n_{sets} = n_{same} + n_{different}$$ Now we can easily find out the number of ways to pick k sets from \(n_{sets}\). A collection of 20 cards will contain a minimum of 1 set and a maximum of 6 sets. Thus number of ways to collect 'at the most' 6 sets can be defined as $$n_{6\,sets} = \sum_{k = 1}^{k = 6} \binom {n_{sets}} {k}$$ Thus to find out N ways in which we can collect 20 cards that does not contain a set is $$ N = \binom {81} {20} - n_{6\,sets}$$ ImplementationWe can now write code that
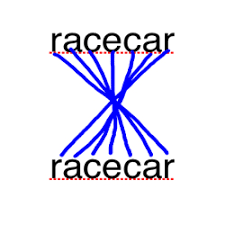 Please refer to the palindromic pangram problem on this page. AnalysisLet \(A_{p}\) represent a word and let \(A_{pr}\) represent its reverse. Let \(A_{1}\), \(A_{2}\), ..., \(A_{n-1}\), \(A_{n}\) be the subsequences of \(A_{pr}\) such that all of \(A_{1}\) \(A_{2}\) ..., \(A_{n-1}\) are valid words while \(A_{n}\) could be a valid word, but must be a palindrome. Then we can say that the following is a pangram for word \(A_{p}\): $$Pangram_{A_{p}} \leftarrow \sum_{i = 1}^{i = n-1} A + A_{p}$$ Let us verify if this holds true with the following two examples cited in the problem statement: $$Pangram_{daffodil} \leftarrow lid + off + a + daffodil$$ where $A_{n}$ = 'd' which is a palindrome, but not a valid word! and, $$Pangram_{ayatollahs} \leftarrow shallot + ayatollahs$$ where \(A_{n}\) = 'aya' which is a palindraome, but not a valid word! It can be easily observed here that \(A_{1}\), \(A_{2}\), ...,\(A_{n}\) are all prefixes of \(A_{pr}\). Or we can think of them as substring q of string \(A_{pr}\). We also know then that a suffix tree is a good data structure to do string matching! Algorithm
Please refer to the mystery M function problem on this page. Analysis(defun m (i j k) Let us look at the exit conditions for this recursive function ’m’. One of the exit conditions is when k equals zero. Now look at the recursive call. The recursive call fetches a value of k by replacing it with a call to ’m’ while decrementing k. As such k will reach 0, when it will return 1. So it can be seen that the terminating condition of k equals zero returns 1 which is used as a value for k itself. EvaluationThe evaluation will never terminate!
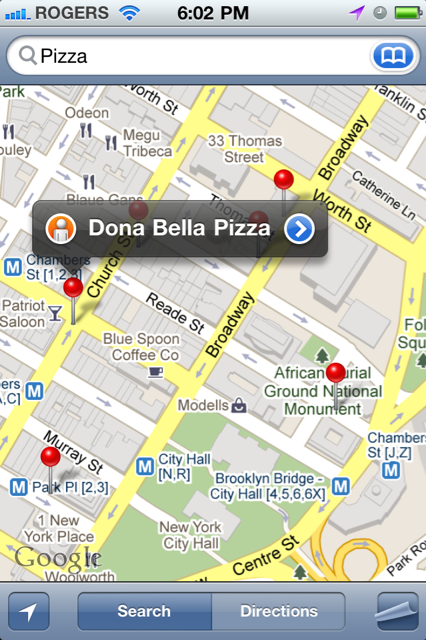 Please refer to the landmarks web app problem on this page. AnalysisThe key part to solve here is to pick the nearby landmarks. As such we need to define what nearby means. Since each landmark’s latitutde and longitude are defined, we can define for a given landmark lm, whose latitude and longitude are \(lm_{lat}\)and \(lm_{long}\) respectively; a nearby landmark nlm with latitude and longitude \(nlm_{lat}\) and \(nlm_{long}\) such that: The nearest \(nlm_{lat} < lm_{lat}\)OR The nearest \(nlm_{lat} > lm_{lat}\) OR The nearest \(nlm_{long} < lm_{long}\) OR The nearest \(nlm_{long} > lm_{long}\) In other words, the nearest landmark in any direction to the given landmark assuming the given landmark as a center. If we can now think of a landmkark as a vertex on a graph, then the neighboring vertexes of a given landmark will be those landmarks that satisfy the above definition. AlgorithmBuild a B-Tree where key is latitude and another where key is longitude. Now do a inorder traversal of this BTree while adding a landmark as a key to a hash table and its nearest landmarkes as values. Then given a landmark, we just look up in the hash table to find the nearest landmarks. ImplementationIn order to make the web application responsive, it would be nice to load the page with a javscript hashtable of landmarks and its nearby landmarks.
 Please refer to the decrypting the two time pad problem on this page. AnalysisThe following are the problem characteristics. It is an instance of:
Algorithm
ImplementationI have not implemented this algorithm. But the analysis and the requirements of the problem do indicate that an approximate solution is requi Ared and the quality of it will hence depend upon (drawn from the algorithm) the chosen reference text. As such we may have to try out the implementation with mulitple chosen texts. References Please refer to the ascii a-maze problem on this page. AnalysisA maze is a grid of n * m cells. Given a maze, we can detect from a given cell k, which cell you can move to next. This is a defintion of a directed graph. Thus we can model a maze as a directed graph where each cell of the maze is a vertex and its neighbors are the cells you can navigate to from the given cell. Now the start and end cells are defined as the bottom left and top right cells. Counting the lowest row as 1st row and left most column as 1st column while assuming m rows and n rows in the maze, the start cell is (1,1) while the end cell is (m, n). The problem then becomes of finding the shortest path between the start and end cells. AlgorithmThis is the Breadth-First-Search algorithm to find shortest path between two vertexes.
The important piece here will be to transform the ascii maze into the graph and ignoring the cyclic vertexes while finding the shortest path. |

MeI am a 3D graphics software engineer. 
Archives
December 2011
Categories
All

me @ delicious
|
 RSS Feed
RSS Feed
