
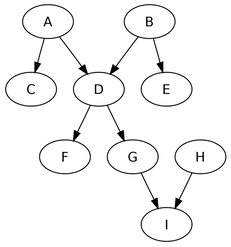
 Please refer to the add-a-gram problem on this page. AnalysisGiven a 3 letter word, let us assume, we can find out the 4 letter words that are its add-a-grams. We can then expand this to a n letter word pointing to its (n + 1)th add-a-gram. We can obviously model this as a directed graph where each word points to its add-a-grams. Further since there is no possibility of an add-a-gram pointing to its possible source, this will be an acylic graph. Thus we have a directed acyclic graph representing the add-a-grams. AlgorithmThe problem then is of finding the ’longest path’ in the directed acyclic graph. In our case each edge will have a weight of 1.
First we build a hash table where key is the length of the word and values are the words of those length. Then we build the directed acylic graph such that each vertex is the word ’w’ and its neighbors are its add-a-grams obtained by searching through the hash table those words which are 1 more character in length than the given word ’w’.
0 Comments
 Please refer to the word numbers problem on this page. Before I even explain how I tried to solve this problem, you can download and install the code from my bitbucket word-nums repository. After you have tried finding numbers and are convinced that this application does solve the problem, if you are interested in understanding the details of the solution, you may continue reading. AnalysisThe characteristics of the problem are:
Finally, we first need to convert a given number into its word equivalent. The algorithm to do the conversion is described next.  Some analysis 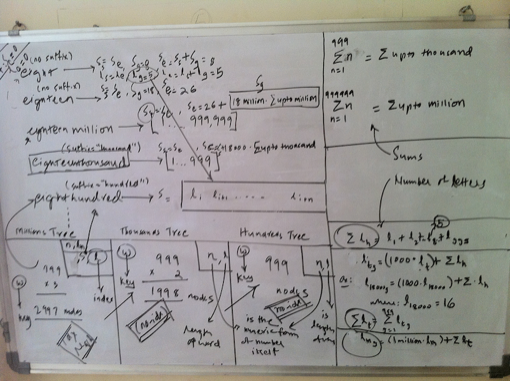 Some more analysis Converting a number into it's word equivalentIt can be observed that any number is a repetitive pattern of 1 to 999, scaled by thousand for the next pattern and by million for the next and so on. In our case, we scale only upto millions. Thus it would suffice to generate a word equivalent of a 3 digit number between 1 and 999 and use the scaling factor of thousand and million based upon the number of times the pattern is repeated. Further for a 3 digit number, any digit that occurs in unit’s or hundred’s place is a simple look up from the numeric form of the digit to its word form. However the translations for the digit in ten’s place are best described as quirky as 1 in ten’s place means ten if followed by 0 in units place, 11 if followed by 1 and so on. The digits 2 to 9 in ten’s place are less quirkier as the conversion depends only on the digit and not by the digit in unit’s place as is the case for 1 in ten’s place. Thus,it is now possible to generate word equivalent for any number by splitting it into patterns matching a 3 digit number and using the appropriate scale such as thousand and million. The code that generates a word equivalent is shown here. (defun join-words (words) How about brute force?Having identified that an index b-tree is a suitable data structure for our needs, and we have already figured out the generation of a word equivalent, it would be straightforward to generate an indexed b-tree of billion numbers. We can then traverse the tree in sorted order to update the index which is the number of letters covered. Then a simple lookup using the index should suffice. However this approach will suffer from the problem of time to build an index, sorted b-tree as we have a billion numbers. The time is dependent upon the processing power and memory availabe on the machine that builds the data structure. Of course, we could use a large number of machines (or multiple cores) so that we can build the data structure faster. Even in that case, we still have to ensure that we distribute the numbers evenly between the machines so that all parallel computations complete around the same time! But would there not be an elegant way out? It turns out, there is! Elegant way outWe have already identified that there is a repititive pattern of digits. We used this property to generate a word equivalent. Then the same property should be helpful in lexicographical ordering of the words. Is this true? Let us find out. If we sort just the first 999 numbers, the sorted list (A) looks something as shown below: 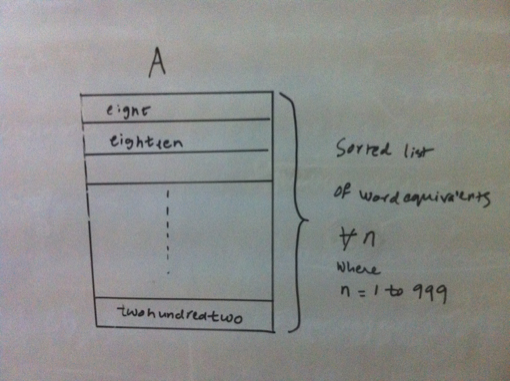 First 999 numbers in lexical order Now consider the numbers upto 999,999. These are actually a group of 999 numbers where each group starts with [1000;2000;3000;999,000]. Their word equivalents are [onethousand,twothousand,threethousand,..,ninehundredninetyninethousand]. These word equivalents can be generated by adding the suffix ’thousand’ to the word equivalents of numbers from 1 to 999, which is our pattern (building block). So the sort order for the numbers upto 999,999 remains the same when expressed as a group of numbers as described above. Further each such group contains an additonal 999 numbers, which happen to be 1 to 999. The same argument holds true for numbers upto 1 billion. Just that a group in this case will contain 1 million numbers. Overall the three sorted lists A, B, C respectively of multiples of one, thousand and million are shown below. 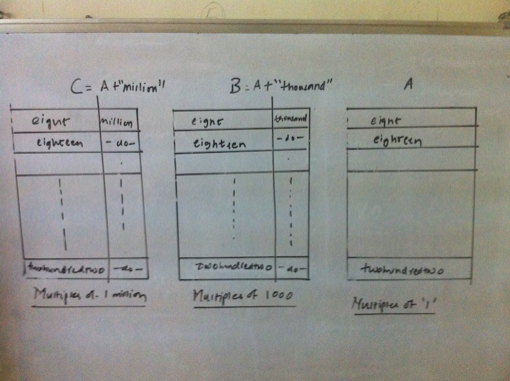 Multiples of 1, 1000 and 1,000,000 in lexical order Since any number is either a million or thousand or hundred, we just need to know the lexicographical position of the successive scales starting from the highest scale. Thus for a number that is multiple of million, I need to find out the sorted order position of the millionth part of the number, followed by that for the thousandth part and then for the hundredth part. As we have a billion numbers to look at, we need to maintain the following 3 databases:
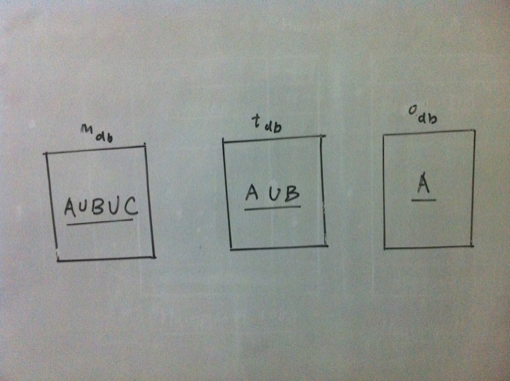 Databases containing multiples of (1 1000 and 1000000), (1 and 1000) and 1 in lexical order Now if we can precompute the number of letters counted and the sum, we can have an elegant solution to our problem. Precomputing the sum and number of lettersSince we know the word equivalent of a number, we also know its length. For a number that represents a multiple of one, its length can be denoted as: \(l_i\). A number that is multiple of 1 is the smallest scale and we need to look no further. So the overall sum of all letters in word equivalents of numbers that are multiple of 1 can be represented as: $$l_{ones} = \sum_{i=1}^{999} l_i$$ Now lets consider a number that represents a multiple of thousand. Let the length of its word equivalent be denoted by \(l_t\). Since such a group contains further 1000 numbers, the length for the group can be described as $$l_{tg} = l_t + l_{ones}$$ So the total number of letters covered upto 1 million can be denoted as $$l_{thousands} = \sum_{g=1000}^{999000} l_{tg}$$ Similary for a multiple of millions, the formula is $$l_{mg} = l_m + l_{thousands}$$ So the total number of letters covered upto 1 million can be denoted as $$l_{thousands} = \sum_{g=1000}^{999000} l_{tg}$$ Similary for a multiple of millions, the formula is $$l_{mg} = l_m + l_{thousands}$$ Here we do not need to compute the overall summation as we are scaling only upto a billion. On the same lines, the sum of numbers covered can also be computed. $$s_{thousand} = \sum_{i=1}^{999} i$$ $$s_{million} = \sum_{i=1}^{999999} i$$ $$s_{tg} = t + s_{thousand}$$ where t = (1000 or 2000 or ... 999000) $$s_{mg} = m + s_{million}$$ where m = (1000,000 or 200,000 or 999,000) AlgorithmNow we can describe the entire algorithm. As a first step, we build the 3 databases which contains the multiples of one, thousand and million. Each database is an indexed btree. Next we update the btree which contains the multiples upto million with the sum and letters covered using the formuale described in the previous section. Now given the number of letters covered, which is actually an index into our database, we look up the number starting with the millions database using this index. We find the first node n in the btree such that for this node n, if index is \(k_found\), $$k_{found} >= index$$ If \(k_{found}\) is index, we have found our number. Else, we navigate to the previous node in the tree and check if that is the node we are looking for by computing the number of letters covered. Otherwise, this node forms a part of number and serves as a key into the next database, which is thousands database if it is multiple of thousand or one’s database. Before searching in the next database, we update that database with the letters and sums on each node, as the key is a prefix to each number in the next database., Every node of the binary tree contains the following data:
(defun find-integer (idx db &optional (n 0) (sum 0) (vals (list 0 0))) A visual depiction of the algorithm is shown below. 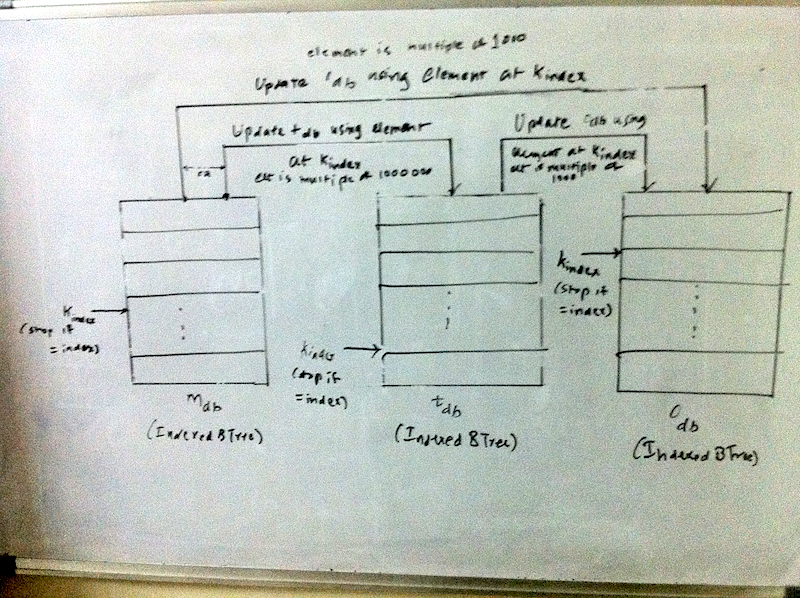 Word numbers algorithm Since we use an indexed B-Tree, the efficiency of the algorithm while creating and updating a btree is $$O(n (log n))$$ while looking up the number is $$\approx O(log n)$$. Hence the overall efficency is: $$O(n (log n))$$ DisclaimersThe solution is tested on SBCL 1.0.39 on Mac OS X 10.6 using cl-elephant as the btree implementation. I would like to emphasize that the solution was not generated in the sequence described above. I did some detailed whiteboarding and tried out code snippets and finally figured out the solution. Further, the solution uses only \(999 * (3 + 2 + 1) = 5994\) nodes. So an in-memory version of a binary search tree should as well suffice. Since I had a ready to use disk based indexed B-Tree implementation, I chose to use that. What is the number at 51th billion letter?As per my solution, there is no number that ends at 51 billion. In fact, there is a number that ends at 51 billion and one. And that number is 676465328. The sum of numbers upto that point is 206392395198132239862723. From the code run at REPL * (word-nums:find-at 51000000001)  Please refer to the sling blade problem on this page. Before I even explain how I tried to solve this problem, you can download and install the code from my bitbucket ol-titles repository. After you have tried finding overlapping titles and are convinced that this application does solve the problem, if you are interested in understanding the details of the solution, you may continue reading. AnalysisThe problem requires us to find the longest chain of overlapping titles. The following can be identified from the problem details:
Thus we have a directed graph to reprsent the titles. Now the problem of finding the longest chain gets transformed into the problem of finding a path within this graph which covers as many vertexes as possible. At least theoretically, then the longest chain will be the path that covers each vertex and that too exactly once, since we are not supposed to repeat titles. 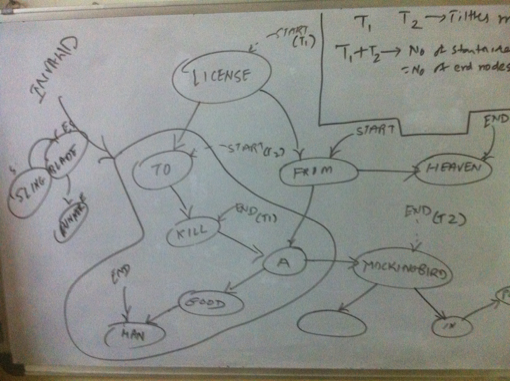 Analysis While prototyping all the different ideas and approaches in code, I used the cl-graph library by Gary King. So wherever you read something as ’I tried’ it implies as in ’tried in code’. I have not shown all the code but only the one that I chose as a solution. Traveling Salesman ProblemThe problem of finding the path in a graph which covers each vertex exactly once is the traveling salesman problem and we know it is an NP Complete Problem. In our case, since we have directed edges, where weight of each edge is 1, it becomes the Hamiltonian cylce problem. But we have a directed graph at hand. A heuristic to find the Hamltionian path is to find minimum spanning tree of a graph and finding the shortest paths between the vertexes of the tree ordered by depth first traversal. However this works only for undirected graphs. Anyways, how do you find tree of a directed graph? However this analysis clearly shows that we cannot have a chain that covers all titles unless its an undirected graph. Attempt 1: Assuming an undirected graphGoing by the previous argument, I tried with an undirected graph and produced an ordering of the vertexes in depth first traversal of the minimum spanning tree. Now while finding the paths between these vertexes, I actually look at the directed version of the graph. The problem with this approach is that you find a long chain only if you reach a vertex that is a leaf late enough in the cycle. This is evident from the visual below. Hence this transformation is not suitable for our problem. 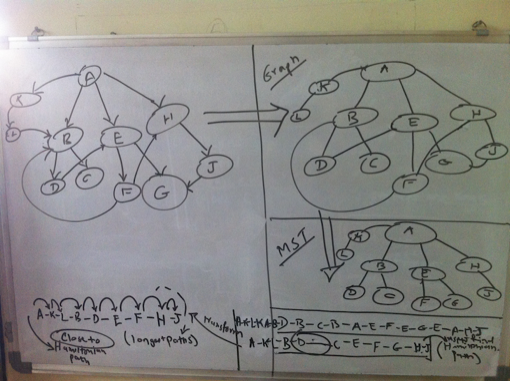 Attempting with a MST of undirected graph Again we could actually find the optimum branchings (minimum spanning tree) of a directed graph, but still the vertexes obtained from the branching could suffer from the same problem. So I dropped this idea. Attempt 2: Topological SortAs a first step, I removed all the edges from the edge that would result in creation of cycles. Now I have a directed acyclic graph and you can do a topological sort. I then tried to find the path between two vertexes at the opposing ends of the sorted list of vertexes as shown in visual below. Again this usually produced a chain of around 20 titles. Again here ideally we must try to find the path between the pairs of vertexes which are ordered by their position in the topological sort. Still attempting to find the path by successively moving deeper into the sorted list at both the ends gave me a fair enough idea to follow this path or not. Not happy with the results, I abandoned this idea as well. 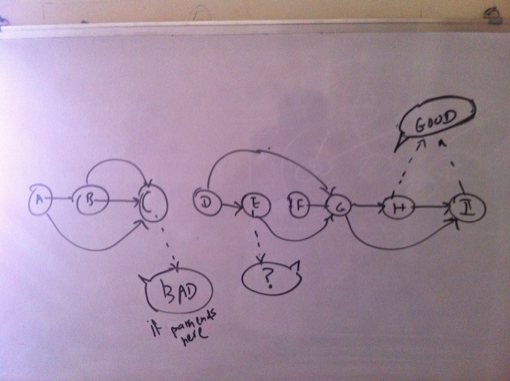 Attempting with a topological soft of directed acyclic graph Attempt 3: Cyclic ApproachFinally this is what I came up with. I first found out if they directed graph is connected. It was disonnected. So I found the largest connected component. I chose this component to find the longest path. Next I figured if it was cyclic or not. It was. So I found all the vertexes which belong to a cycle. Next was to find a path for each cyclic vertex such that the path contains only cyclic vertexes. The largest such cyclic path would be my answer to the longest chain. This is the property that I applied here usefully. In order to prove a vertex is cyclic, we can determine a path where the vertex in question is the start as well as the end node. However the coroallary of this is that every vertex on the the cyclic path is cyclic itself. As such we can find a path of overlapping titles where each vertex on the path is cyclic, because for a given cyclic vertex, one of its neighbors has to be cyclic! Implementing this, I was able to find out a chain of 230 titles. Thus by using the heuristic of finding longest cyclic path so that it contains only cyclic vertexes, I was able to find a heuristic solution to the longest chain. We can also claim that the longest chain which is a cyclic chain cannot be more than the total number of cyclic vertexes. 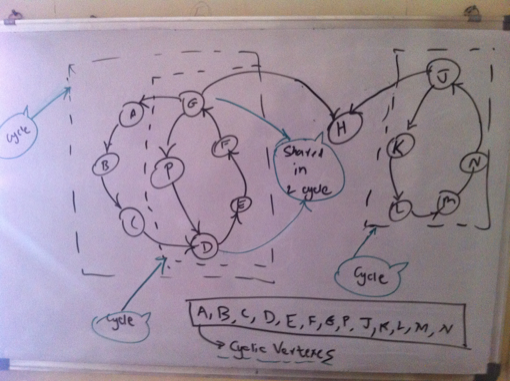 Finding out the largest cyclic path containing only cyclic vertexes AlgorithmThe algorithm can thus be described as: Build a directed graph of the titles where each directed edge (u, v) represents an edge from title ’u’ to overlapping title ’v’. Then find all the cyclic vertexes of the largest connected component of the directed graph. Find the cyclic path for each cyclic vertex such that the path contains only cyclic vertexs. The longest such path is the longest chain of overlapping titles, given the heuristics.
Since the main task is to find out the cyclic vertexes (using depth first search), let us assume we have a graph G=(V, E) which represents the largest connected component. Since we find out if each vertex V is cyclic, the efficiency turns out to be: \( O(V . (|V| + |E|)) \approx O({|V|}^{2}) \) When we find the cyclic path, we do not do a depth first search and only look up in the list of cyclic vertexes for the next valid vertex for the given vertex  Any programmer who is learning Lisp and sticks with it, eventually comes face to face with Macros. While trying to come to terms with the concept of macros and its usage, he often comes across a statement which can be stated as ”Once you really understand macros, you will understand why lisp needs parentheses.” Though the statement is correct, you may not find a direct or simple explanation of its meaning. I attempt to do that here. Defining a new control flow operatorLet us assume you have a requirement to process only non prime numbers, given a list of numbers. Also assume, you have a function available that tells you given a number, if it is prime or not. Intutively, this is what you want to express ”Unless it is a prime number, do the processing” given the fact that we have a predicate to check primes. However what you see is that C does not have unless control flow operator. So you write: if(!prime(...)) { However, this is what you would have preferred and in fact you would read the above code as below: unless(prime(...)) { You think ”It would have been great, if the language simply allowed me to add the operator”. You might also naively think that this must not be so hard. If I can write and abstract my own computations as functions, why cannot I introduce my own operators, specific to my problem? The answer (if you may hazard a guess), is that it is not so simple to provide the feature to add new constructs. We have to dig deeper to find out the answer. What happens to the code?Let us now navigate into the compiler world. Sticking to the compiler basics, let us try to find out what shape your code transforms into when the C compiler handles the if construct. As you may know, the compiler front end builds a parse tree. So your source code is transformed into a tree as shown below. (I have shown the tree for the if operator). 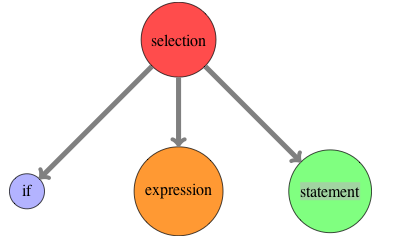 Parse tree for if operator Now let us try to employ our imagination. If we assume that there was an ’unless’ operator like if, what would the abstract syntax tree look like. It is shown below: 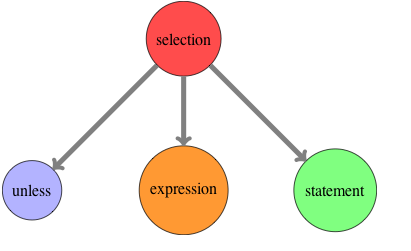 Parse tree for unless operator Thus we have found a potential solution to allowing a language to introduce a new operator. Whenever C compiler encounters an unless keyword, it has to generate the syntax tree something similar to figure . For that we have to look into the process it employs for the existing ’if’ operator. The reason why C compiler can transform ’if’ is that it ’knows’ the syntax of ’if’ beforehand. It is embedded inside the compiler. So in order for the C compiler to understand new ’unless’ like constructs, we have to define a mechanism to specify the syntax of your new operators. And therein lies the crux. How can the compiler understand new syntax?What then could be the simplest way to help the compiler understand new syntax? It would be by having a consistent, uniform syntax. Is the syntax of C consistent, uniform? No. Is the syntax of Lisp consistent, uniform? Yes. In fact, uniform syntax is equivalent to no syntax. Now you get why parentheses are required. They lend very well to the requirement of uninform syntax.[1] Hence I conclude that macros are not impossible but very hard in other languages because:
Recommended Reading   [1] This is also related to the concept of internal and external domain specific languages. Any which ways, external domain specific languages are nothing but bloated tools on top of languages which got the design of syntax wrong in the context of allowing new operators or a probelm / domain specific language to be defined (which is nothing but a set of related operators to solve the problem at hand).
[2] This does not imply that simply a uniform syntax allows a compiler to handle new syntax with ease. There is some more important stuff in addition to uniform syntax, but I understand that it is a key requirement.  Before I even explain how I tried to solve Suodku, you can download and install the code from my sudoku repository. After you have tried a few unsolved Sudoku boards, and are convinced that this application does really solve Sudokos, you may continue reading to find out the design and implemenation details. Representing the boardHere I describe my attempt at solving Sudoku using Lisp. Since Lisp is my favorite programming language, it is but natural that I choose to use it to solve Sudokus. Enough lisp adulation and before I digress too much, let us find out what the solution looks like. Please note that the code is tested only on SBCL. Since a Sudoku is a 9 * 9 grid, I decided to use 2D array to represent the sudoku board. Of course sometimes such natural choice of a data structure could be wrong, but if we follow the rule of ”write code fast, then write fast code” (by PG of course) and naturally supported by Lisp; it should not be very difficult to change the underlying data structure if we get to atleast a reasonable approach initially to solve the problem at hand. Sudoku ConceptsWhen I am bored and naturally procrastinating, I indulge in mindless activities like Sudoku. And I am no expert at solving it with pencil and paper. But over a period of time, we pick up some concepts/terms from the problem without even realizing them. The most important such concept in the Sudoku problem for me was that a square could not have any number that appeared in any other square of the row, column or the box to which the square belonged. We could call these other squares as ’friends’ of the square s; though the quality of not sharing seems hardly friendly! It was then obvious that I would need to find out the squares of a given square s. Since our sudoku is a 2D array, the subscripts (i j) of the array would represent each sudoku square. So given the square in the first column, first row the subscripts of which would be (0 0) what would be the friends of the square? In the process of finding the friends of a square; I ended up with the constant friends. It should be noted that this is a refined (after write fast code stage) code; intially all of what you see as constants were functions. Later while optimizing, it was evident that it would be prudent to compute them at compile time and do lookups via hash tables where keys are the subscripts of a square on the 2D array’ed sudoku. This also leads to other 2 corollary concepts of filled and unfilled square. A filled square is that which has a single value assigned to it. An unfilled square is that which has no value assigned to it yet or has one among many possible values none of which are those assigned to any of its friends. Filling up the input boardWhile solving a given partially filled Sudoku (the most natural case; I treat fully unfilled sudoku as a special case) I decided to first fill every unfilled square with the possible choices for it by not considering the values that any of its friends has. Natuarlly here I consider only those friends which have been filled. At this point, we could end up with a few unfilled squares with only one possible choice. Thus it would make sense to update the board. We update the board till no more updates are possible or a contradiction is found. Here comes the rule/concept/constraints of the Sudoku game into play again. The rule states that every row, every column and every box must be filled with each of the digits 1 to 9 without being repeated. So if a square on a row has 1, the column and the box to which the square belongs cannot have any other square with a value 1. If there is a square with value 1; it means there is a contradiction. Aha, now we can write some code to figure out a contradiciton on a sudoku board. This code checks that for every filled square of the sudoku board, none of its friends has the value that it has. The code for checking contradictions is shown here. (defun contradictions? (board) The fact that a sudoku is solved implies there are no contradicitions on the board or the number of squares counted by contradictions should be 81. The function which checks if the board is solved is shown here. (defun solved? (board) Now you can see how we can update the board. (defun update-board (board) At this stage I choose to call the sudoku board as initialized board. The code which initializes the input board is here. (defun update-board (board) With an initailized board we are in a position to find a solution to the sudoku. But how? We know that on the initialized board, every unfilled square has been assigned valid possible choices. So one of the choice for any such unfilled square has to be true. Otherwise, there is a bug in the code which is assigning incorrect possible values to an unfilled square. Thus we could choose at random an unfilled square and assign it one of the possible choices. If we could find whether this assignment is true or false, we could find a solution! How do we find if the attempted assignment is correct?By now it is clear that if the attempted assignment is correct, it will lead to no contradictions and finally to a solution. Otherwise it will be false and lead to a contradiction, so we drop that from the possible values and assign the next possible value and try again to find a solution. Now, can we make use of the discared values as well? Yes. If an assignment is valid; then the rest of the choices are invalid. But each of this choice does exist as a value in some friend. So we find if there exists only a single friend which has among its possible choices; any of the ones we just discarded. Then obviously that discarded choice is the value for that unfilled friend. Similary for a invalid assignment, we check it the value we just discarded can be assigned to any unfilled friend. The code to use discarded values is shown here. (defun use-discarded (val board min) So what unfilled square do we choose? Naturally we want to find a solution as fast as possible. Hence it makes sense to choose an unfilled square with the minimum number of choices. In the worst case, we will find a solution when the last possible choice AlgorithmThe heart of the algorithm can be now described: Assign the next possible choice to the unfilled square with minimum possible choices till we find a solution. After assigning a value, update the board which returns a new board if no contradictions are found.For both valid and invalid assignments, make use of discared values. All this is captured in a function called as try. (defun try (board) Using the cl-utilitiesI use this package in order to copy the 2D array’ed sudoku board as I need to revert back to the old board in case of invalid assignments. Writing fast codeAfter writing a first version of the sudoku solver, I used the time macros and sbcl deterministic profiler as explainedhere. The most important changes made were the conversion to constants of functions dealing with finding friends. That resulted in friends as a hash table with the key being the subscripts for each square of the 2D Sudoku. Some test runsI used the following as samples from Web Sudoku. Easy Sudoku* (setf easy #2A( Medium Sudoku* (setf medium #2A( Hard Sudoku* (setf hard #2A Evil Sudoku* (setf evil #2A( Empty Sudoku* (setf empty #2A( As expected, the empty sudoku got solved in 0.117 seconds. This code seems to have a reasonable performance without any compiler optimization declarations. The entire code can be found here. At the end of the file is code for using sbcl profiler which has been commented. If you test this on SBCL, you can use this profiler or use the profiler available on your lisp implementation. ObservationsThis code is a great fit for using the non deterministic choose and fail operators along with continuations so that I will not have to maintain the copies of the board. I will try updating this code using PG’s macros that add continuations and non-deterministic opeators to CL. That will make the code only more elegant (and may be slower). But all this can be surely concluded only after writing that code!
Further I have not done the algorithmic analysis. Here the candiate would be the try function and as it is recursive, I would have to use recurrence relations. Ideally the path should have been writing a solution using continuations and choose, fail operators and then move to the solution above based upon profiling results! I will update the post when I follow up on the above observations. Feel free to try to solve a sudoku with this code and kindly let me know in case of any comments/suggestions.  Here I attempt to apply my sketch of continuations to understand the code which does depth first traversal of a tree using continuations. This code is from Paul Graham’s On Lisp book chapter 20 which you can find on the page here in Figure 20.3. First let us look at the definition of the function dft which does depth first traversal (dft) without continuations. Now we want to do this traversal using continuations so that we can explore the cdr of a tree at a later point in time. The first step in applying the sketch is to find out when to pause so that a continuation can be fetched and stored for a later restart. Obviously this point is when you are about to traverse the cdr of the tree. As such the call to (dft (cdr tree)) should be enclosed by call/cc expression.This is what you will find in the dft-node function. Now we want to find out what should be next step of the computation when it is invoked? What you want is that when the continuation is restarted, the form (dft-node (cdr tree)) be invoked. And we know that the argument v that is passed to the continuation is what decides the future of the computation. As such the argument to the saved continuation cc will be (dft-node (cdr tree)) Now we cannot save a form (cc (dft-node (cdr tree))) for later restart. Hence it is surrounded by another lambda form which can be stored away. Thus you see (lambda () being saved in a list of continuations. Thus the only question that remains now is how are we going to invoke the continuation? In this case it is already enclosed within a lambda form. So the way to restart it is (cont) where cont is a variable pointing to the continuation. And this is what is done in restart function. But we also know that when a continuation is invoked, the current callstack is replaced by that which existed when the continuation was saved! This is what exactly happens when restart function calls the continuation via (cont). The callstack that is active when restart is being executed is replaced by that which was existing when the continuation was saved. As such any code after (cont) in restart will not execute. Visualizing ContinuationsNow let us apply the visual representation of continuations to this example. You can find the visual below. 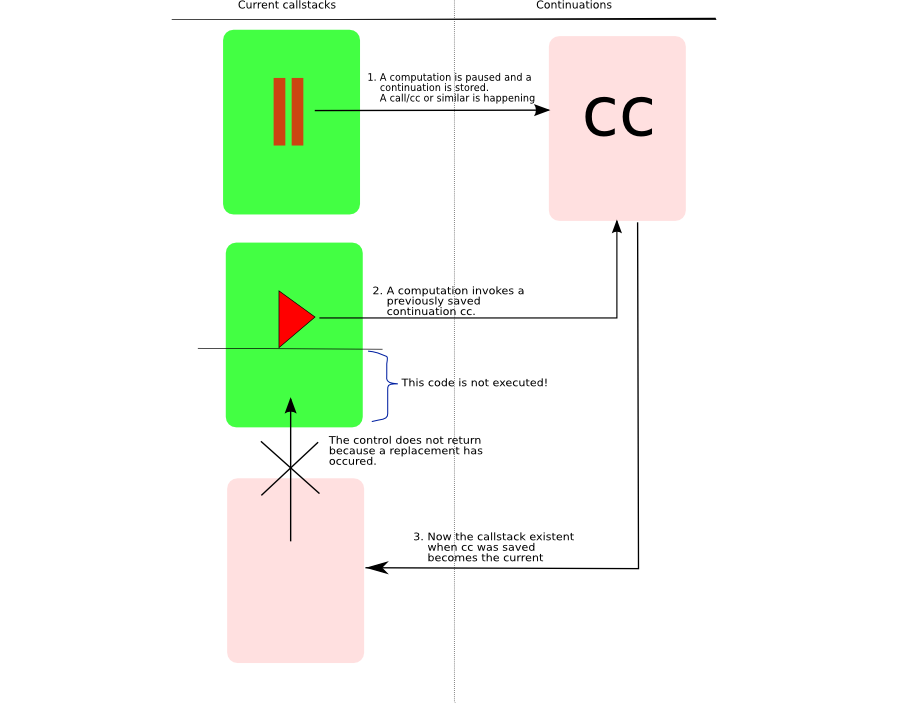 Visualization of Continuations The dft-node is the function where we pause and store the continuation. restart is the function where we invoke the continuation. And when it is invoked, the previous callstack replaces the current one.
Thus you can see that reading and writing code that uses continuations is not so difficult especially when you have a simple underlying sketch in your head. 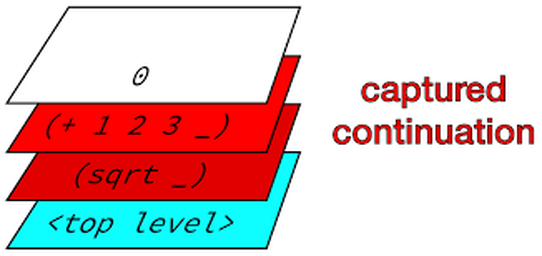 A simple sketch of continuations in programming that makes them easy to understand I always try to derive a simple sketch of any concept that I can then carry around in my head. Let me describe you my sketch of the hard to understand continuations. Let me begin with an example of a simple expression. (+ 3 (* 3 7)) When you evaluate this expression at the top level, it returns 24. Now let us assume that you have this intention to pause the computation at a certain point and to restart the computation at a later time from where you paused it. Let us denote the inner expression (* 3 7) in above expression as e. Let us denote the entire expression as E. After evaluating this expression, what is the next evaluation? Obviously it is (+ 3 21). Now assume that we want to pause the computation when e was evaluated. Then how could we represent the next computation? We could represent it as follows. (lambda (v) (+ 3 v)) where v is the value of expression e. But the above lambda expression could be stored in a variable and invoked later. So if k is a variable representing the above expression, then (funcall k 21) gives us 24 when e evaluates to 21. However we can invoke k as many times as we want with different values. Okay, you may say what is so great about it? This is just normal day to day lisp stuff. Let us go back to your requirement. The requirement is that the computation must restart from where it was paused. In the above case of k, it is not a real restart. A real restart can happen only when you can switch to the same callstack that was existent when you were computing the expression E in question. So we need to have k such that when we invoke k it switches to the same callstack for E. Then we can safely say that when k is invoked the computation continued from where it was left off and the argument v specifying the future (or next step) of the computation. Hence k is a continuation. Thus a continuation for an expression e in a surrounding expression E can be defined as a computation that takes place only when it gets the value for e. In terms of implementation then k is a function of one argument v such that v is the value with which future (next) compuatation is done and that when it is invoked it replaces the current callstack by that which was existent when the continuation was saved. Continuations never returnThe thing to remember about continuations is that the callstack is replaced. What is the consequence? The consequence is that when you invoke the continuation, you cannot return back to the point of invocation since you are now switched to a different (old) callstack. This is what I think makes continuations a bit harder to understand especially when you come from the expereience of writing code where it is assumed to return. C long jumpers (long-jmp) should not find continuations difficult to understand! MechanicsAll this sounds nice but it is equally imporatant to write code that makes use of continuations all the while understanding what is happening beneath. The first thing you want to find out is when to pause. After you identify this point you need to get hold of the continuation (basically a copy of callstack) and store it away so that you can invoke (or restart) it later. Getting hold of a continuation depends upon the language. So if you are in Scheme, you are lucky, because it has inbuilt support for continuations. There is a construct called as call/cc or call-with-current-continuation that expects a function of one argument which it invokes with the continuation object. You can then save this object for later restarts. You can find an example of doing this in Schemehere If you are in common lisp, you can refer to On Lisp chapter 20 which explains how continuations can be added to common lisp using macros. This is a must read chapter as it also shows how the internal implemenation of continuations is a chain of lexical closures. You can read this chapter here. Visual RepresentationVisually we can imagine the saving and restart of a continuation as depicted below. 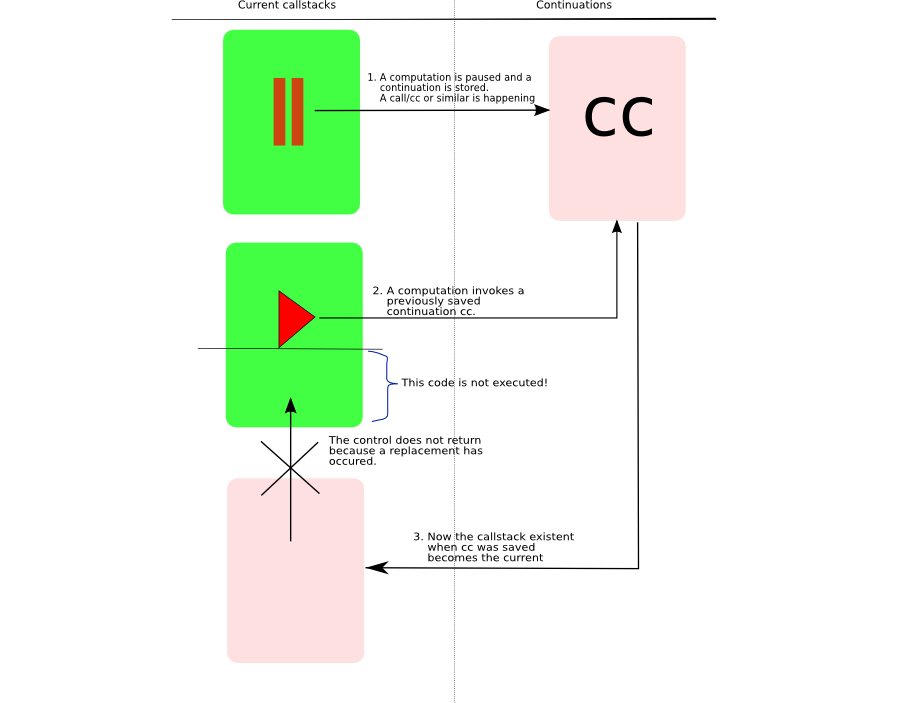 Visualization of continuations Actually I liedLet us first deal with an example going back to our old expression. (+ 3 (* 3 7)) Let the continuation for this be defined as follows (on the REPL). (define saved #f) Now what do you think will be result of the following expression? (saved (saved 21)) If you think 27, then I am sorry to say it is wrong. The answer is still 24. Why? Go back to the replacement of the callstack concept. The current callstack is replaced by the callstack for outer saved which in turned is replaced by that for the inner one. No returns are happening here! Hence the answer is 24. So if you want a continuation to return you could do that. Such continuations are called partial or delimited continauations. The thing then to remember about partial continuations is that you return to the current callstack from where you invoked the continuation. Obviously the consequence is that you can now compose continuations as in (saved (saved 21)) example. As such they are also known as composable continuations. You can find about Scheme support of delimited continuations here. Delimited continatuations can be built on top of continuations. In Common Lisp, cl-cont library adds support for delimited continuations using a code walker. Alternatively one could write these operators in CL using macros. Partial Continuations?Simply because the concepts are in opposition. While continuations do not return, partial continuations return. KaBoom! Anyways, if I had to return the control, why not use continuation itself? If a function f2 invokes a continuation for function f1, I might as well write code that invokes the continuation for f2! That way it is explicit and conforming to the definition of continuation. Alternatively, it could be that partial continuations need to be renamed something else!. Further whenever I apply my sketch of continuations to code that uses continuations it works pretty well. Even when I applied it to code which uses delimited continuations (assuming it were continuations) it worked fine. I still think that partial continuations are an open area for me. The above example of partial continuations has been inspired from the one that appears in Lisp in Small Pieces in section 3.7 within chapter 3. Even this book does not find partial continuations interesting. How to apply the sketch?While working with code that uses continuations, you can apply this sketch as follows. Find out the point at which you pause the computation. At this point you will store the continuation. Also figure out what value you need to pass when you restart the continuation. That will also tell you how you are going to invoke the continuation. And remember that the callstack when the continuation is invoked will be replaced by that which existed when the continuation was stored. Applications of the sketchHere you can find an application of the sketch on depth first traversal of a tree using continuations
 I have a small Lisp program that generates a website's html pages and rss feed, given the original content in latex. However I also wanted to validate the generated html pages, the rss feed as also the site’s CSS. W3C provides a markup validation service to validate your html, css, and rss. Edi Weitz has written a web client library called as Drakma. So I thought of using drakma to validate this website’s generated html pages as also the rss feed xml and css. Drakma library has a http-request method that allows you to send a request to a web server and gives you the return reply. You could then potentially send a web request to whichever markup validation service that you want to consume and scan the returned reply for success or failure. Validating htmlThe html markup validation service api can be found here. From the api, it is clear that we need to send uploaded file and content type parameters when we invoke this service. The code to do this is shown below: (defvar *w3-html-uri* "http://validator.w3.org/check") Now in the returned reply, we need to look for the headers which is the 3rd value in the http-request return reply. Hence nth-value 2. The headers tell us if validation was successful, the number of errors and warnings. Here is some sample code to do that: (defun check (headers) Sample Usage(check (validate-html "/users/me/some.html")) Validating CSSThe CSS markup service api is available here. It can be seen that there is no option to upload file. The CSS validation service when invoked programatically expects the CSS in the form of a string instead of a file. The sample code to do this is shown below: (defvar *w3-css-uri* "http://jigsaw.w3.org/css-validator/validator") The idea is pretty much the same except the parameters change as compared to validating html. You can reuse the check function to find out if the validation was successful, the number of errors and warnings. Sample Usage(check (validate-css (generate-string ”/users/me/site.css”))) Converting your CSS into a string(defun generate-string (file) Sample Usage(generate-string ”/users/me/site.css”) Validating RSSThe RSS validation service api is available here. Though the api mentions the uploaded file, it did not seem to work when I tested it out. Further the results are not returned as in the case of html, css. One has to scan the returned body for the word ’Sorry’. If you think that I am mistaken here, please do let me know. As for now, here is the sorry code :-) (defvar *w3-rss-uri* "http://validator.w3.org/feed/check.cgi") Sample Usage (check-rss (validate-rss (generate-string ”/users/me/rss.xml”))) Thus using drakma you can easily validate your html, css and rss. When validations fail, I just open my browser, browse to the required service, upload the errant file, read the verbose output, fix the errors and recheck with the above functions.
This is especially useful when you have some lisp code to generate the html, rss. Then you could easily plugin the above code to validate them as well. The above code has been tested successfully on SBCL. Let me know in case of any issues. Feel free to use the above code in your programs if you like it. Happy Validating!  For anyone who is interested in learning Common Lisp, this could be a possible approach. This is an approach that I figured out in hindsight. Let us get down to business. The first important choice you need to make is of the OS. Which OS to use?Through my experience, I would say that for learning Common Lisp (as for any other language), Windows is a bad choice (which it is anyways!). So choose any *nix. If you are already a *nix user, you are in safe zone. For Windows users, I would recommend using VirtualBox (a virtualization software) to install a Linux. Ubuntu is what I would recommend. Why a *nix?The simplest reason is that the entire CL ecosystem (at least open source) is geared towards *nix than Windows. You may opt for LispWorks, which provides a Windows environment. There is also LispBox setup that you can use. But in the long run, I expect that you may experience pain though I cannot verify that since I have not gone down that path! Even Windows setup just simulates the *nix setup. Hence it is better to go the virtualization way I think. So choose something like Ubuntu running inside VirtualBox if you are Windows user. Which implementation do you choose?I would recommend using SBCL. Clisp, CMUCL are also other good choices. Thus, choose SBCL as your CL implemenation for your learning process. Do not worry too much initially about various implementations and differences between them. As you work your way through learning CL and get proficient you will also learn to work with different implementations. It is very simple to install a CL of your choice on a *nix.Just use the package management system of your *nix to install the lisp implemenation of your choice. Having chosen an OS and a Lisp implementation, the next obvious question is which IDE to use? Honestly, Lisp does not need an IDE. Which editor to use?From my experience, I have arrived at this conclusion: ”Lisp REPL itself is the IDE”. So what you need is just a simple, powerful text editor. Lisp has virtually no syntax, except that you need the editor to help you with the parentheses. I prefer nvi. However here I should point out that I am in a minority. Most of the Lisp community prefers Emacs and Slimecombination. To be honest, I started out with the same; but later switched to vi. So if you already an emacs user, you might choose Emacs + Slime. If a vi user, you might go ahead with vi. I find using vi and the lisp REPL a sufficiently powerful and a simple setup at the same time. With this our setup is ready. It is *nix + SBCL + (EMacs + Slime / Vi). Where to begin?I would recommend that you give sufficient time to work through Lisp. So if you come from a weaker language background, it may take some time finding your feet. To start with, you can begin with either of these 2 books. Practical Common Lisp (PCL) by Peter Siebel or Ansi Common Lisp (ACL) by Paul Graham. I chose the latter simply because I prefer chapters with exercises to solve which PCL lacks. But that in no way takes away from PCL. I would recommend starting off with any book, using the other as the companion.   The important point here is to work through which ever book you like. By work through it, I mean it is not only importantly to thoroughly understand what is being explained and to solve the exercises, but to also have a few questions. In addition, type out every piece of code and ensure that it works. You will learn a lot through this simple but hard process. At the end of whichever book you chose to begin with, you must have the big picture in place. Do not expect to attain mastery over advanced topics such as macros or closures. It is important to have a simple mental mode of Lisp here. The simplest model I found is a sketch of the Lisp eval function. By now you must be comfortable working with Lisp type of code, downloading and installing libraries, using ASDF. You must have a simple clear Lisp model in your head. Since I came from a Java (OO) background, I completely skipped the CLOS part. Simply because I did not want to give myself a chance to go back to writing Java type OO code in Lisp! Of course, CLOS is way more powerful than the standard OO that you get in other langauges, but I skipped CLOS initially for a valid reason. And that was to grasp the Lisp style of coding. Now you are ready to tackle the advanced topics in Lisp such as closures and macros. The best book to master these is obviously On Lisp.  This is what I did and it worked well for me. On Lisp is more about utilizing the power of Lisp via macros and closures. But if you read closely it is a book full of problems and solutions. As such read through the problem PG tries to describe and solve it using whatever Lisp knowlege you have. Then compare your solution to that in the book. It will teach you a lot more than simply even working through the book. Doug Hoyte has rightly pointed out that On Lisp is a zero or one book, that is, either you understand it or you do not. If you cross the On Lisp road, you are well on your way to become a very productive programmer. About example projects in the PCL, ACL and On LispInitially I just glanced through the example projects in ACL. After working through On Lisp upto chapter 18, I worked through the examples in both ACL (chapters 15,16,17) as well that in On Lisp (chapters 19 through 24). The inference and objects chapters 15 and 17 respectively in ACL merge with chapters 19 and 25 of On Lisp. After working through the above, you can as well treat say PCL example projects as problems to solve. Or you can pick up a problem to solve of your own and rake up a Lisp solution. The first such thing I did was to write a Lisp program to generate the website that you are now browsing! I was inspired by the chapter 16 in ACL to generate html to write a solution to generate my website. How much time would it take?This really depends upon the individual. But as with any learning, consistency is more important. Do not learn anything hard with long breaks in between. Since I also have a day job and other things to take care of, it took me around 10 months to work through these 2 books. But today I can say that it was worth the effort. Common Lisp Libraries and QuickLispWhen you sit down to write your own real Lisp code, it will extend to more than 1 lisp file. In that case you have to ensure the order in which the files are loaded is correct to manage the dependencies. In addition, you will also try to use existing libraries as much as possible. So you also have to ensure the dependencies of your code on these libraries All of this is taken care of you via Lisp packages, see Erran Gat’s guide for packages and ASDF (a make like tool for Lisp).Common-lisp.net and Cliki are good sources of common lisp libraries. There is now an excellent way of managing your Lisp Libraries. QuickLisp. Its a GOD send. Language Reference I use Ansi Common Lisp Appendix D Language Reference as my reference guide. For detailed reference, Common Lisp The Lanuage, Second Edition is the choice. You can also access the Lisp documentation online. What next?If you reach this far, you will surely be motivated to use Lisp as much as possible. You can join some open source Lisp project to make contributions. In addition, you can also spend some time (again regularly) to work through these following Lisp books.       |

MeI am a 3D graphics software engineer. 
Archives
December 2011
Categories
All

me @ delicious
|
 RSS Feed
RSS Feed
